Инструмент отсева неэффективных работников на этапе подбора: дерево решения
Напоминаю, что Websoft и Лаборатория "Гуманитарные Технологии" договорились об интеграции своих продуктов, и теперь у клиентов Вебсофта есть возможность проводить тестирование через Вебтютор. Так что воспринимайте данный пост как подспорье в решении задачи отбора
Еще покажу, что можно делать с помощью тестов на этапе подбора
Еще покажу, что можно делать с помощью тестов на этапе подбора
Новый для нашего рынка инструмент принятия решения на основе данных кейса Кейс: отсев неэффективных работников на этапе подбора.

Напомню, мы протестировали кандидатов на входе, они в дальнейшем показали определенные результаты, что позволило разделить их на 1 - неэффективных (или тех, кого не стоило бы брать в компанию) и 2) всех остальных или тех, кого можно принимать.
В предыдущем посте я показал возможности логистической регрессии. Мы выявили две шкалы - Sp и Do, которые позволяют отличать неэффективных от всех остальных.
Главный недостаток логистической регрессии - интуитивно непонятные результаты, диаграмму ROC не предъявишь совету директоров.
Требуется более наглядный инструмент. Таким инструментом является технология Trees - или дерево принятия решения.
Итак,
Напоминаю, что мы выявили две шкалы, которые значимо различают неэффективных и остальных:
- Sp
- Do
(про то, как выявили, что такое значимость различий, читай
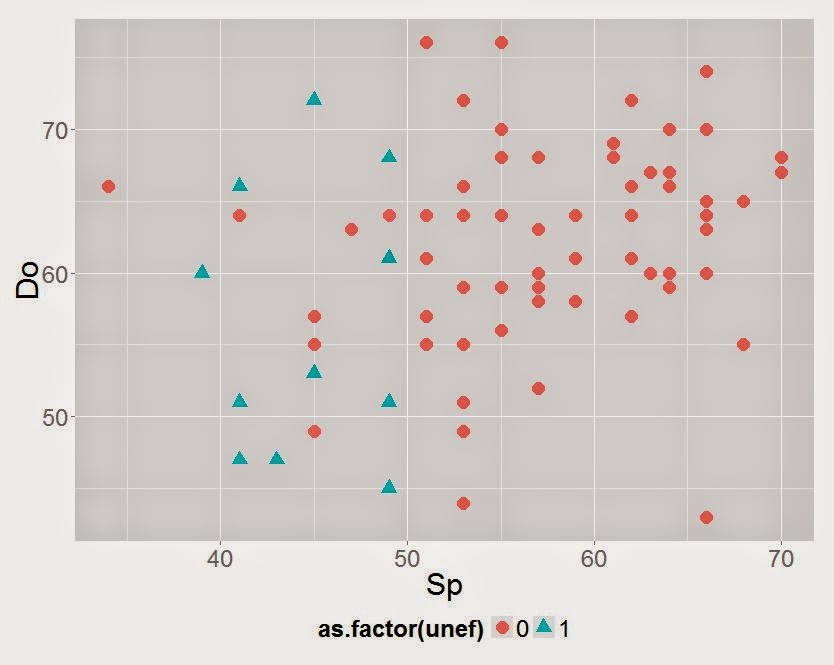
Визуализируем взаимосвязь тестов и показателей эффективности.
На этой диаграмме
- шкала X - показатели кандидатов по шкале Sp теста CPI,
- шкала Y - данные шкалы Do теста CPI;
- зеленые пирамидки - неэффективные работники,
- красные точки - работники, качество работы, которое устраивает работодателя.
График сам подсказывает решение, верно? Прям так и просится провести границу по линии 50 Sp.
Посмотрим, что нам скажет инструмент Trees
Обращаю ваше внимание, что это не человек рисует данное дерево, а машинка (программа R или она же Rstudio). Для спецов в области статистики сообщаю, что я здесь не рассматриваю проблемы оверфитинга и т.п., моя задача - показать инструмент. Инструмент нам предлагает следующую инструкцию принятия решения по кандидату:
- если показатели кандидата по шкале Sp больше или равно 50, значит берем на работу
- если меньше 50, смотрим шкалу Do.
- если Do больше или равно 54, берем кандидата, если меньше, отклоняем кандидатуру.
Красиво?




