"Все врут" или что говорят большие данные
На днях прочитал книгу "Everybody Lies: Big Data, New Data, and What the Internet Can Tell Us About Who We Really Are" - очень рекомендую.
Одна из идей книги - мы сильно недооцениваем количество данных которые можно получить, анализируя поведение людей в сети (поисковые системы, социальные сети, и т.п.).
Можно ли понять что интересует eLearning специалистов?
В последнее время в российском сообществе eLearning специалистов часто обсуждаются стандарты, которые используются для сбора и обработки данных по процессу электронного обучения.
Основные альтернативы:
1) SCORM - последняя ревизия в 2004 году, это было давно
2) TinCan он же CMI5 он же xAPI он же Experience API - альтернативный новый стандарт
3) есть и альтернативное мнение - стандарты вообще никому не нужны, но это тема для отдельного разговора
А что говорит Google Trends? Какие стандарты интересуют специалистов по всему миру (ибо сомнительно, что кто-то кроме специалистов набирает такие запросы)?
Результаты по ссылке и на картинке (SCORM пока впереди):
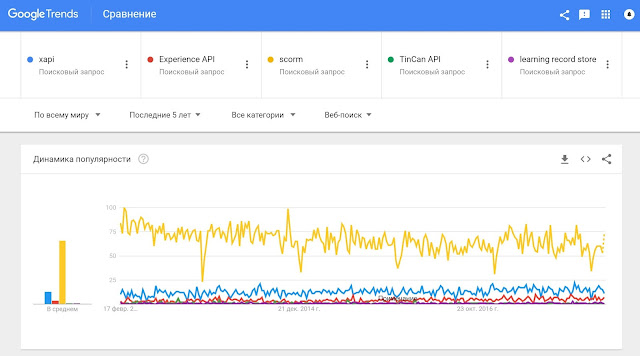
Вообще, в Google Trends много всего можно увидеть. Например, понять растет ли реальный интерес к микро или мобильному обучению так же быстро как увеличивается количество упоминаний этих тем в статьях и выступления про HR-тренды.
Есть о чем подумать...
Одна из идей книги - мы сильно недооцениваем количество данных которые можно получить, анализируя поведение людей в сети (поисковые системы, социальные сети, и т.п.).
Можно ли понять что интересует eLearning специалистов?
В последнее время в российском сообществе eLearning специалистов часто обсуждаются стандарты, которые используются для сбора и обработки данных по процессу электронного обучения.
Основные альтернативы:
1) SCORM - последняя ревизия в 2004 году, это было давно
2) TinCan он же CMI5 он же xAPI он же Experience API - альтернативный новый стандарт
3) есть и альтернативное мнение - стандарты вообще никому не нужны, но это тема для отдельного разговора
А что говорит Google Trends? Какие стандарты интересуют специалистов по всему миру (ибо сомнительно, что кто-то кроме специалистов набирает такие запросы)?
Результаты по ссылке и на картинке (SCORM пока впереди):

Вообще, в Google Trends много всего можно увидеть. Например, понять растет ли реальный интерес к микро или мобильному обучению так же быстро как увеличивается количество упоминаний этих тем в статьях и выступления про HR-тренды.
Есть о чем подумать...




